
Indexing the web is an integral part of search engines, allowing them to crawl and register web resources for later inclusion in search results. However, there are occasions when it is necessary to exclude certain technical pages and sections from indexing.
In general, indexing happens through crawling websites by search engine crawlers. Thus, these search engine spiders follow every link and visit every internal and external page they find.
In simple terms, indexing is simply parsing all the sites on the Internet by following and crawling all the links it finds.
The main methods of indexation management.
1. Using robots.txt
The most common and simple method is to use the robots.txt file. This text file is located in the root directory of the website and includes rules for search engine crawlers. For example, "User-agent: *" indicates all robots, and "Disallow: /" prohibits them from indexing all pages of the site. Learn more about setting up robots.txt.
2. The "noindex" meta tag in the Head tag in HTML code
The use of the noindex meta tag in HTML code is an effective method of managing the indexing of web pages for search engines. This tag allows webmasters to clearly define whether a particular page should be indexed or not, which is crucial for SEO strategy and search engine indexing control.
The noindex meta tag tells search engines that they should not include this page in their indexes, which means that it should not be placed in the search results database. This can be useful in various situations, for example, when you have a large number of filter pages and you want to exclude only some of them from indexing.
In the example <meta name="robots" content="noindex, follow">, the "noindex" attribute means that the page should not be indexed, and the "follow" attribute allows search engines to follow the links on the page. This means that although the page itself will not be included in the index, search engines may index other pages to which it links.
How to check if your website is indexed?
There are 2 main methods of checking whether our site is indexed: Search Console and Google search itself, let's analyse these methods in more detail below.
Checking indexation in the Search Console
To check the indexation of your site in Search Console, you should first of all register it in this software. Then, after 24 hours, we will be able to see the first analytics. The indexing data is located in this place:
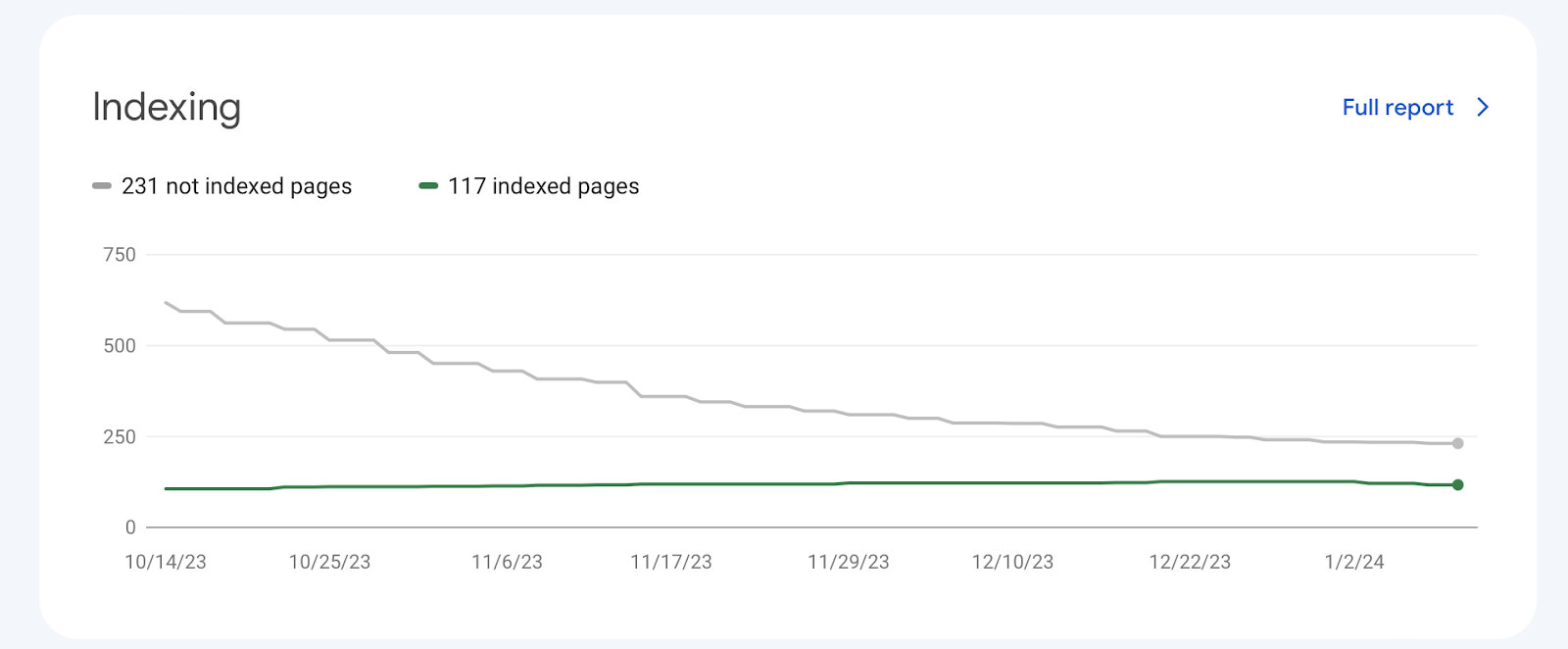
However, there is one disadvantage of this check, namely, the data will be provided only to registered websites, so we cannot find out whether any other website has been indexed.
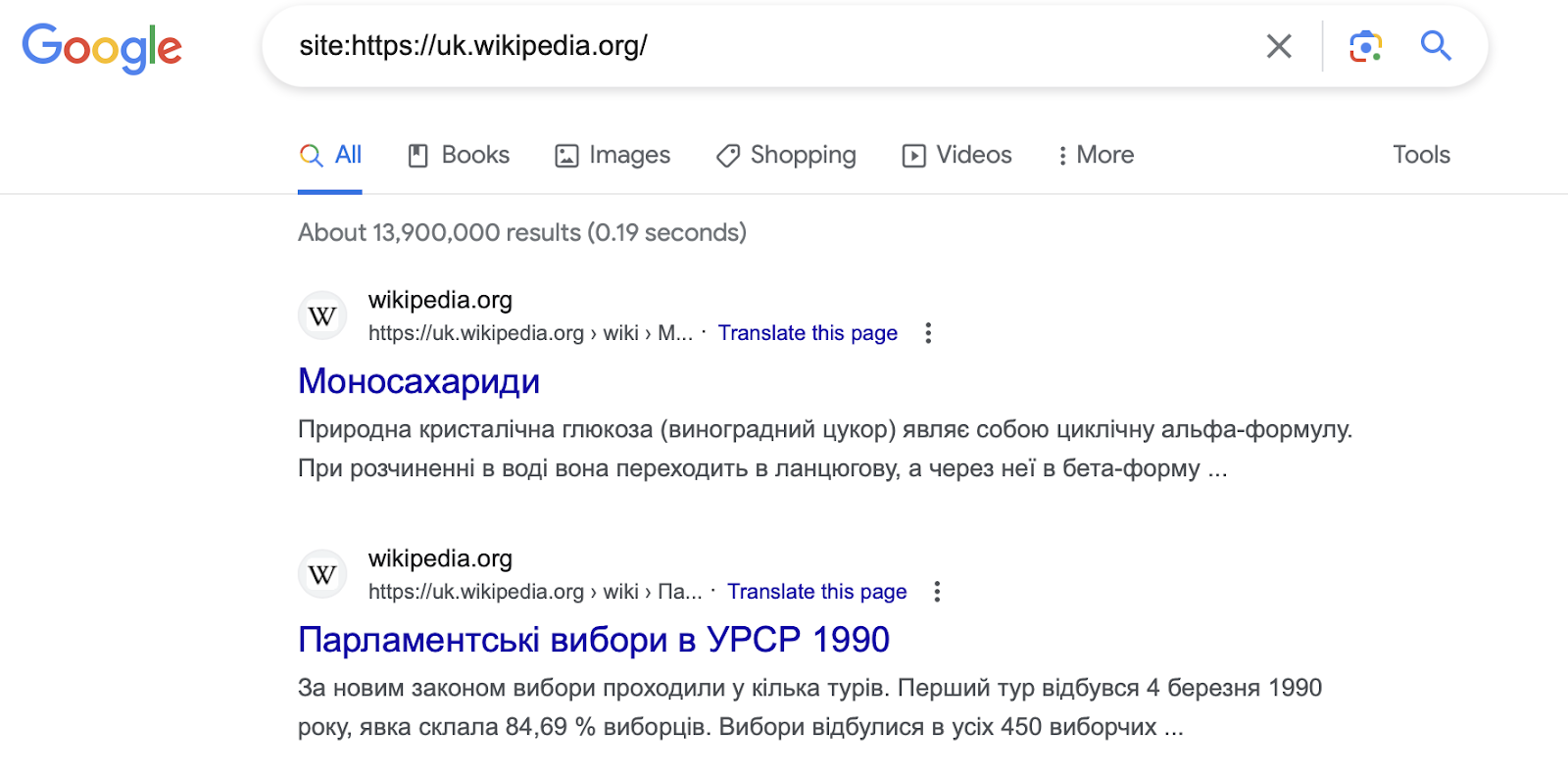
Checking indexation in Google search
This method is the most popular and simple. In Google search, you need to enter the following phrase "site:https://domain.com". Where site: is the search phrase, and https://domain.com is the site you want to check. Example:
Conclusions.
Ensuring optimal protection against indexing includes the important aspect of combining different methods at the same time. In this case, using a combination of robots.txt and the "noindex" meta tag in HTML code may prove to be the most effective solution.
The robots.txt file provides instructions to search engines about which parts of the site to index and which parts not to index. However, this may not always be enough to ensure that important information is not included in search results. An important addition here is the use of the "noindex" meta tag, which allows you to precisely define the indexing settings for a particular page.

Similar articles
All articles




