
Indeksowanie w Internecie jest integralną częścią wyszukiwarek, umożliwiając im skanowanie i rejestrowanie zasobów internetowych w celu włączenia ich do wyników wyszukiwania. Istnieją jednak wyjątki, w których niezbędne jest wyłączenie niektórych stron i sekcji technicznych z indeksowania.
Ogólne indeksowanie odbywa się poprzez skanowanie stron internetowych przez roboty indeksujące wyszukiwarek. W ten sposób pająki wyszukiwarek podążają za każdym linkiem i odwiedzają każdą wewnętrzną i zewnętrzną stronę, którą znajdą.
Innymi słowami, indeksowanie to po prostu analizowanie wszystkich stron w Internecie poprzez śledzenie i skanowanie wszystkich znalezionych linków.
Główne metody prowadzenia indeksacji.
1. Korzystanie z pliku robots.txt
Najczęstszą i najprostszą metodą jest użycie pliku robots.txt. Ten plik tekstowy znajduje się w głównym katalogu strony i zawiera reguły dla robotów indeksujących wyszukiwarek. Na przykład "User-agent: *" wskazuje wszystkie roboty, a "Disallow: /" zakazuje im indeksowania wszystkich stron danej strony. Dowiedz się więcej o https://svitsoft.com/blog-single/what-is-robots-txt-and-how-to-set-it-up-correctlykonfigurowaniu pliku robots.txt.
2. Metatag "noindex" w tagu Head w kodzie HTML
Wykorzystanie metatagu "noindex" w kodzie HTML jest efektywną metodą zarządzania indeksowaniem stron internetowych dla wyszukiwarek. Znacznik ten pozwala webmasterom jasno określić, czy dana strona powinna być indeksowana, czy nie, co ma zasadnicze znaczenie dla strategii SEO i kontroli indeksowania przez wyszukiwarki.
Metatag "noindex" informuje wyszukiwarki, że nie powinny uwzględniać tej strony w swoich indeksach, co oznacza, że nie powinny umieszczać jej w bazie danych wyników wyszukiwania. Może to być przydatne w różnych sytuacjach, na przykład, gdy masz dużą ilość stron z filtrami i chcesz wykluczyć tylko niektóre z nich z indeksowania.
W przykładzie <meta name="robots" content="noindex, follow">, atrybut "noindex" oznacza, że strona nie powinna być indeksowana, a atrybut "follow" pozwala wyszukiwarkom podążać za linkami na stronie. Oznacza to, że chociaż sama strona nie zostanie uwzględniona w indeksie, wyszukiwarki mogą indeksować inne strony, do których prowadzi link.
Jak sprawdzić, czy strona jest indeksowana?
Istnieją 2 główne metody sprawdzania, czy nasza strona jest zaindeksowana: Search Console i bezpośrednio w wyszukiwarce Google, przeanalizujmy te metody bardziej szczegółowo.
Sprawdzanie indeksacji w Search Console
Aby sprawdzić indeksację strony w Search Console, należy przede wszystkim zarejestrować ją w tym oprogramowaniu. Następnie, po upływie 24 godzin, będziemy mogli zobaczyć pierwsze dane analityczne. Dane dotyczące indeksacji znajdują się właśnie w tym miejscu:
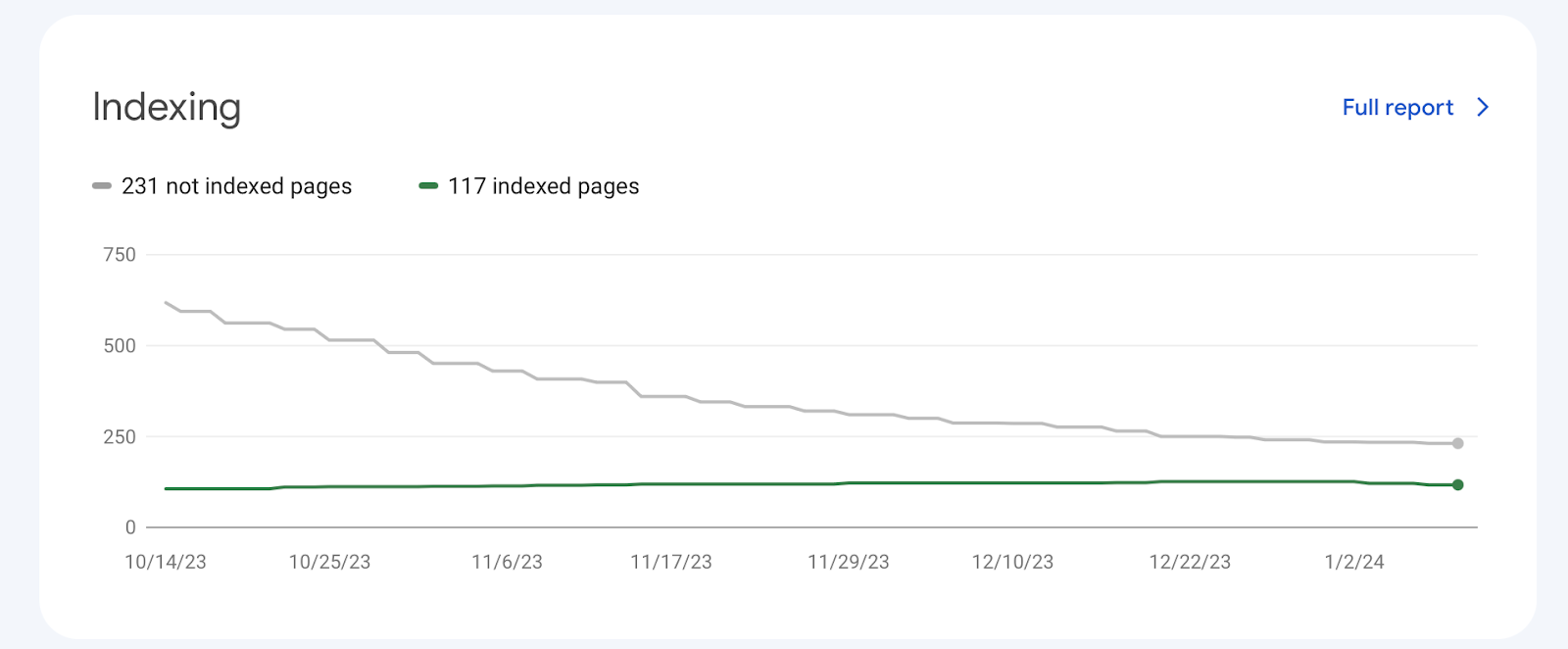
Jest jednak jedna wada tego sprawdzenia, a konkretnie dane zostaną udostępnione tylko zarejestrowanym stronom, dlatego nie możemy dowiedzieć się, czy jakaś inna strona została w ten sposób zaindeksowana.
Sprawdzanie indeksacji w Google Search
Ta metoda jest najpopularniejsza i najprostsza. W wyszukiwarce Google należy wpisać następującą frazę "site:https://domain.com". Gdzie site: to wyszukiwana fraza, a https://domain.com to strona, którą chcesz sprawdzić. Przykład:
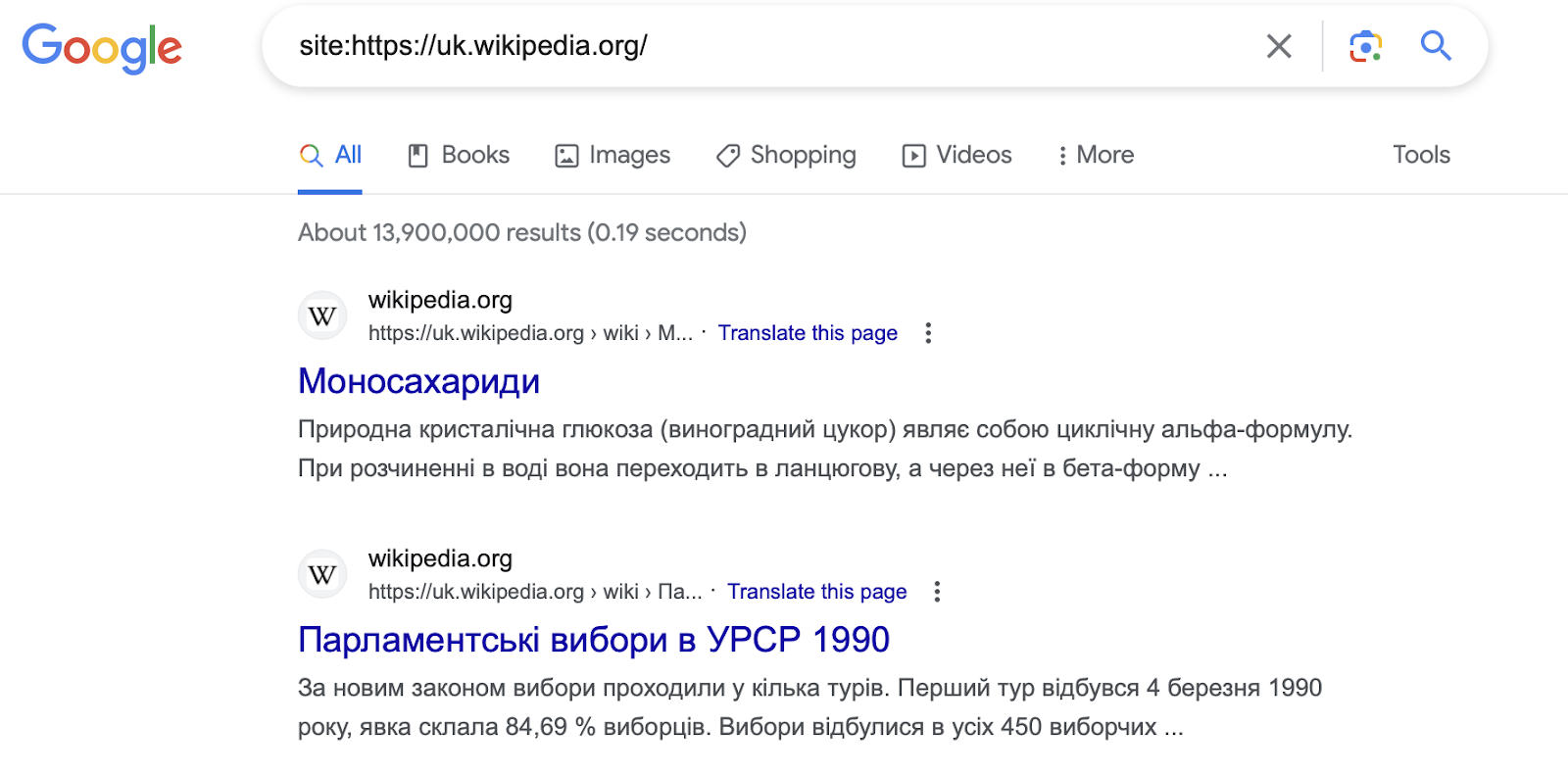
Podsumowanie.
Zapewnienie optymalnego zabezpieczenia przed indeksowaniem obejmuje ważny aspekt łączenia różnych metod jednocześnie. W tym przypadku użycie kombinacji pliku robots.txt i metatagu "noindex" w kodzie HTML może być najskuteczniejszym rozwiązaniem.
Plik robots.txt zawiera instrukcje dla wyszukiwarek dotyczące tego, które części strony powinny, a które nie powinny być indeksowane. Jednak nie zawsze może to wystarczyć, aby zapewnić, że ważne informacje nie zostaną uwzględnione w wynikach wyszukiwania. Ważnym dodatkiem jest tutaj użycie metatagu "noindex", który pozwala precyzyjnie zdefiniować ustawienia indeksowania dla konkretnej strony.

Podobne artykuły
Wszystkie artykuły




